
Category: JavaScript

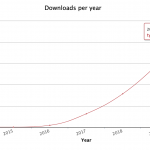
Turn your Mac OS Photos library into a Web photo album September 27, 2020



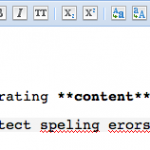
Announcing Typo.js: Client-side JavaScript Spellchecking March 31, 2011
Uploading form data and files with JavaScript (Mozilla) January 30, 2010
Facebook Image-to-Email: Broken Again November 16, 2007
Convert Facebook e-mail images to actual e-mail links September 11, 2007
Extending JavaScript May 5, 2007